

- Communications
Announcing: Search Inside Your Videos with Greater Accuracy
In the enterprise and in higher education, video content that can’t be searched has little value.
The majority of business and academic video content is long-form. Town hall meetings are often 30-60 minutes in length. Recorded classroom lectures typically run an hour. Online training videos can range from 15 minutes to well over an hour. According to Cisco, long-form video made up 64% of all video traffic in 2014, a figure that is expected to grow.
With long-form video, traditional “YouTube-style” search is insufficient. Even if videos are extensively tagged, YouTube-style search can only help users find the start of the video. It doesn’t help them find the specific points in the video where their search term actually appears.
Finding content inside a video’s talk track and other presented materials is the challenge of enterprise video search. It’s what makes a 15, 30, or 60-minute video valuable because it allows employees to search and quickly access the content as easily as they would in email, documents or web pages.

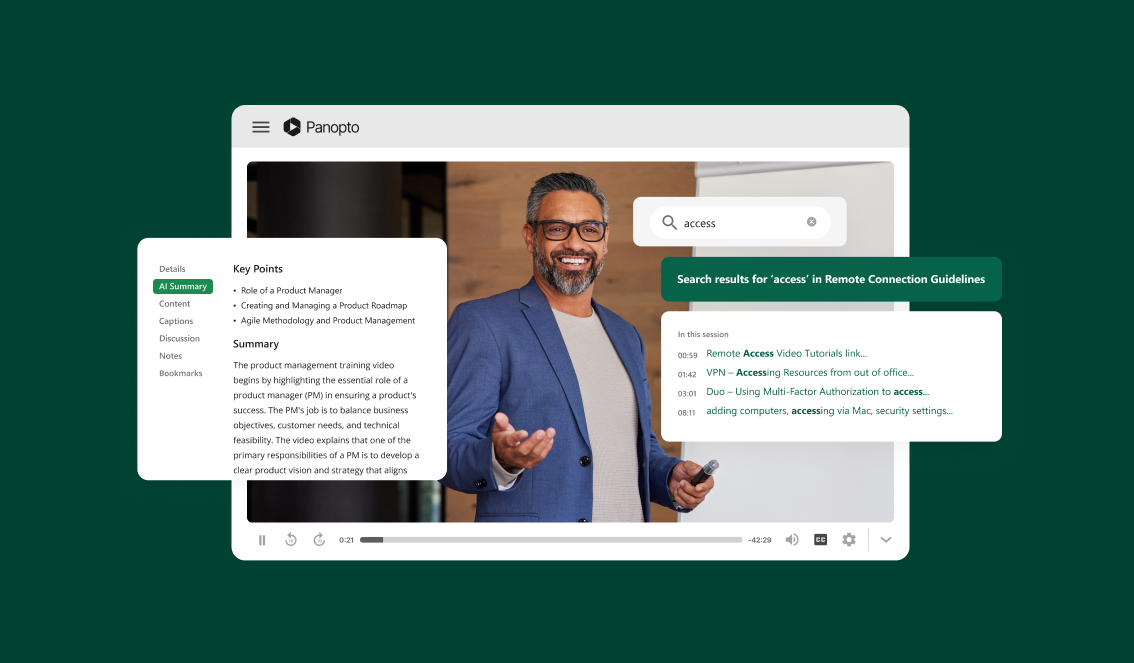
In 2014, Panopto launched Smart Search to address the shortcomings of traditional video indexing. Smart Search automatically indexes words in the presenter’s talk track (a process called automatic speech recognition or ASR) and all words that appear in the video (a process called optical character recognition or OCR). OCR is particularly important for business and academic videos, which typically include formal presentation materials or on-screen demonstrations.
 Optical character recognition ensures that corporate presentation materials and the content of on-screen demos can be searched.
Optical character recognition ensures that corporate presentation materials and the content of on-screen demos can be searched.
Today, we’re excited to announce an important update to Smart Search. In the next couple of days, customers on the Panopto cloud will notice significant improvements in the quality of OCR search results.
To provide a sense of the new algorithm’s accuracy, we created two tests. The first shows how well Panopto’s OCR handles text of gradually decreasing font size. On a 1920×1080 screen, character recognition was accurate down to, and including, 8-point font.
 The font size test measures OCR accuracy as the font size decreases. The test began with 40-point font. Results were 100% accurate.
The font size test measures OCR accuracy as the font size decreases. The test began with 40-point font. Results were 100% accurate.
 The test concluded with 8-point font. Even at this small font size, OCR accurately recognized 100% of the onscreen text.
The test concluded with 8-point font. Even at this small font size, OCR accurately recognized 100% of the onscreen text.
The second test shows the accuracy of Panopto’s OCR as contrast ratio decreases. In this case, the contrast ratio is measuring the luminance between the text and the background.
 The contrast ratio test measures OCR accuracy as the contrast between the text and the background decreases. The test began with black text on a white background.
The contrast ratio test measures OCR accuracy as the contrast between the text and the background decreases. The test began with black text on a white background.
You’d expect text recognition to work well when the text is black (RGB 0, 0, 0) and the background is white (RGB 255, 255, 255). As the text color gets lighter , however, contrast ratio decreases. This makes it harder for OCR to accurately distinguish the text from the background.
In our test, we used 16-point font, which is the default size for desktop web browsers. We began with a contrast ratio of 21 (black text on a white background) and gradually decreased contrast ratio to 1.7 (RGB 200, 200, 200 on a white background). As context, a contrast ratio of 1.7 falls far below the W3C’s Web Content Accessibility Guidelines (WCAG 2.0), which specify that the presentation of text have a contrast ratio of no less than 4.5:1.
Yet, even at this low contrast ratio, Panopto’s OCR engine was able to accurately recognize 100% of the text.
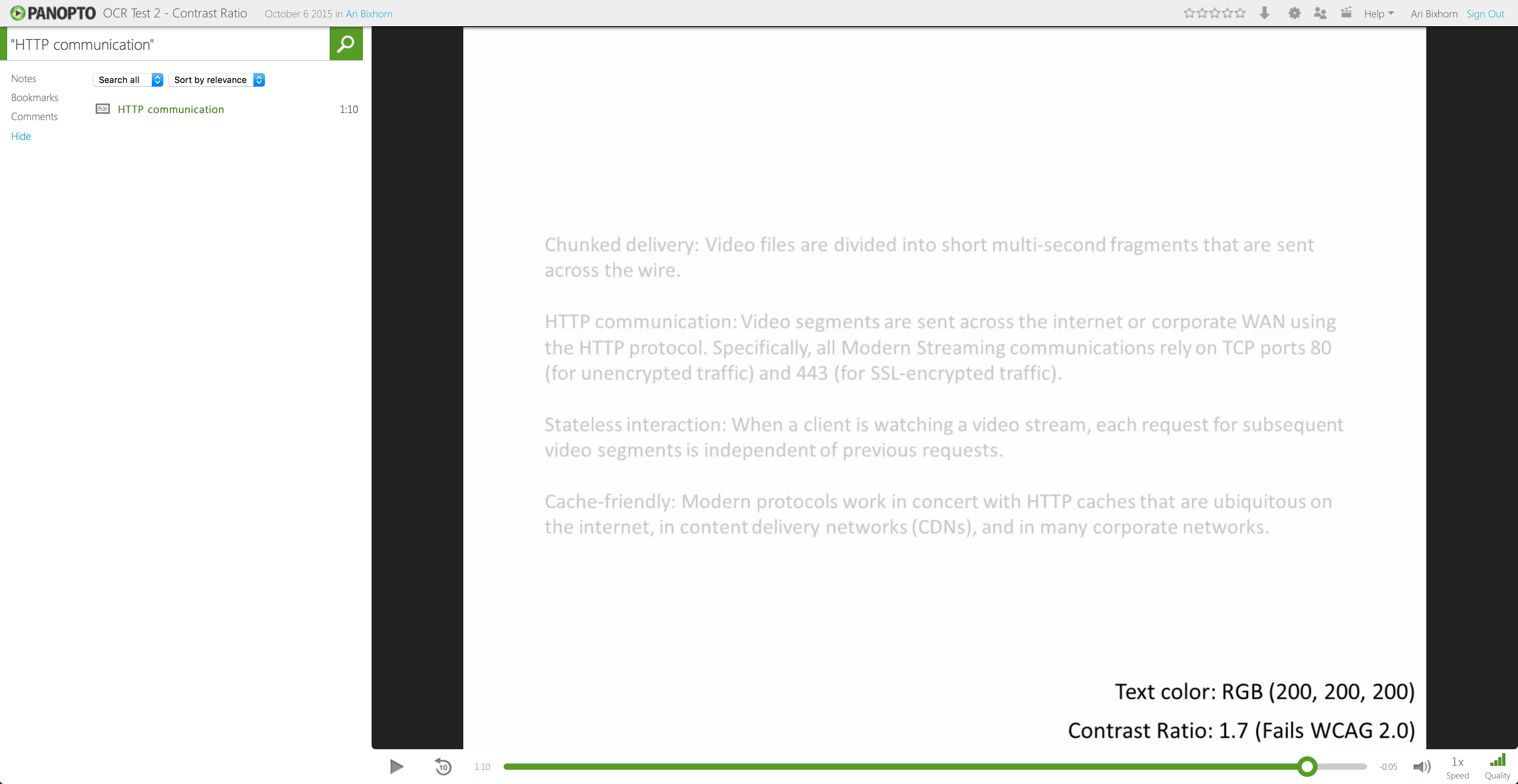 Even at an extremely low contrast ratio, Panopto’s OCR accurately recognized 100% of the onscreen text.The more video your business or university captures, the greater the need for a video search engine that indexes the actual content inside videos. With today’s announcement, we’re making the best video search engine even better. For more information about Panopto’s Smart Search, or to learn how our video content management system can improve the way your organization communicates and shares information, request a free trial of our software today.
Even at an extremely low contrast ratio, Panopto’s OCR accurately recognized 100% of the onscreen text.The more video your business or university captures, the greater the need for a video search engine that indexes the actual content inside videos. With today’s announcement, we’re making the best video search engine even better. For more information about Panopto’s Smart Search, or to learn how our video content management system can improve the way your organization communicates and shares information, request a free trial of our software today.